
Why World Models Built on RL Won’t Deliver Real Intelligence — And What It Takes
Think You Can Piecemeal Real Intelligence? Think Again.


OpenAI, Google, Meta, and xAI are chanting the same mantra now: video-scale pretraining through multimodality will somehow give their models real-world understanding.
Big Tech’s AI labs are playing musical chairs, every time a “missing piece” gets louder, they scramble for a new seat. The problem isn’t the chairs; it’s the missing engine: cognition.
In August 2025, they flagged Continuous Learning as a missing piece then learned quickly that you can’t brute-force incremental learning from continuous inputs with billion$. So, they shifted the bet to another hole in the hull: World Models.
What is a world model, really? It’s an AI’s internal understanding of how the world is structured, what is currently true, how things change over time, what actions to take, and what consequences follow from actions, it is dynamic, self-updating, not a static dataset.
None of Big Tech’s AI labs will get there by treating “world models” as a scale problem when the problem is “understanding”. If it can be brute-forced, they’ll fund it because in their playbook scale substitutes for structure.
OpenAI positioned Sora 2 as “Video Models as World Simulators” boasting more “physics-accurate” control. Google DeepMind is on its third “Genie” world model and keeps pushing robotics via RT-2/Gemini Robotics. Meta touts V-JEPA’s abstract, predictive representations. xAI is staffing up with Nvidia veterans to build world models and even promises a brand new AI-generated game by 2026.
On paper, that sounds like progress. In practice, it’s the same capacity theater, replacing text with more pixels and more GPUs and calling it intelligence.
They’re wrong, again by putting the cart before cortex.
Put plainly, the “curated” world they train on - simulators, staged datasets, even photoreal video are toy universes next to the real world’s mess. More data from simpler worlds does not alchemize into understanding of complexities in the real world; it just amplifies patterns from the sandbox and that’s why surface correlations don’t survive contact with reality. Understanding demands structure: concept formation, causality, persistence, counterfactuals, consequences, feedback and improvisation.
Reinforcement learning doesn’t bridge that gap. Its currency is reward—a scalar proxy that works in short-horizon games and breaks under real-world ambiguity, delays, and shifting constraints. “Reward is enough” is elegant in theory; in practice, the signal collapses into score-chasing. Credit assignment over long temporal spans becomes guesswork; exploration in combinatorial spaces becomes unaffordable; policies overfit the training loop’s quirks instead of generalizing causal structure. Even Richard Sutton has drawn the boundary: a genuine world model should let you predict what will actually happen next, not merely the next token in the training distribution. That line separates reward optimization from real-world understanding.
In other words, you don’t get a dynamic world model from a bigger data funnel through a robot’s eyes and ears.
So how do you get both a world model and real intelligence?
You get it by scaffolding for a changing world. You build a cognition-first architecture that deeply integrates the capabilities to learn, understand, reasons remember, updates its own model, and evolve - autonomously and continuously with one unifying discipline that brings it all together, real-time incremental learning.
Real-time incremental learning is where the engine runs. Here are the required (and implied) integrated capabilities that come together for real-time incremental learning:
Perception (structured sensing): Convert raw streams (text/audio/video/sensors) into typed, uncertainty-aware signals the system can reason over.
Concept formation (ontology): Maintain explicit, editable concepts - objects, relations, causes, actions, space, time, numbers (both real and abstract) so new facts attach to the right meanings and generalize beyond one scene.
Understanding: Map observations to concepts and relations; know why, not just what.
Goals & utilities (directed behavior): Bake in goals, constraints, and trade-offs so learning and actions are optimized and purposeful, under constraints rather than just matching patterns.
Active, Self-directed learning. Curiosity, active exploration, and experiment design are non-negotiable and continuous. The system must choose what to observe next, not passively drink from a static dataset. This learning is incremental, contextual, conceptual, adaptive and autonomous in real-time.
Memory (persistent & editable): Keep episodic and semantic memory that’s versioned, provenance-grounded, and reversible - add/amend/quarantine without collateral damage.
Context & temporal reasoning: Track who/what/where/when/under-which constraints; know what changed, what still holds, and for how long.
Reasoning & planning: Simulate counterfactuals, chain multi-step causes to outcomes, evaluate plans before acting, and validate results afterward.
Metacognition (self-monitoring): Detect contradictions and uncertainty, decide when to stop/ask/replan, and learn how to learn over time.
Dynamic world model (live map): Maintain a continuously updating model of entities, physics, agency, and affordances that persists across tasks and scenes.
Policy (action ↔ feedback): Turn beliefs into actions, capture outcomes, and route feedback to update beliefs, closing the loop every step.
Belief revision (incremental updates): Assimilate one fact at a time with provenance and confidence, updating only affected nodes/links; no bulk retrains.
Causal inference and credit assignment tie actions to consequences across time, explaining why outcomes occurred so lessons transfer to new contexts; uncertainty calibration quantifies confidence and carries it through perception, inference, and action, so the system knows when it might be wrong; and conflict resolution with safety guards isolates contradictions, arbitrates via provenance and rules, fails safely, and escalates for clarification rather than corrupting the model; and provenance with full auditability records who/what/when/how/under-what-conditions for every assertion and rule, keeping learning transparent, reviewable, and reversible.
Pulls it all together as one Integrated Loop.
The Integrated Loop: Perception ↔ Memory ↔ Understanding ↔ Reasoning ↔ Context ↔ Metacognition ↔ Dynamic World Modeling ↔ Policy (Action).
These capabilities make real-time incremental learning possible, and real-time incremental learning, in turn, makes the world model evolve with every action.
Real intelligence demands all twelve - integrated, not bolted on. Get the architecture right first; only then do data, compute, and energy matter. Reverse the order and you’re scaling failure, faster which is the path they’re on now. That’s why we built INSA—the Integrated Neuro-Symbolic Architecture.
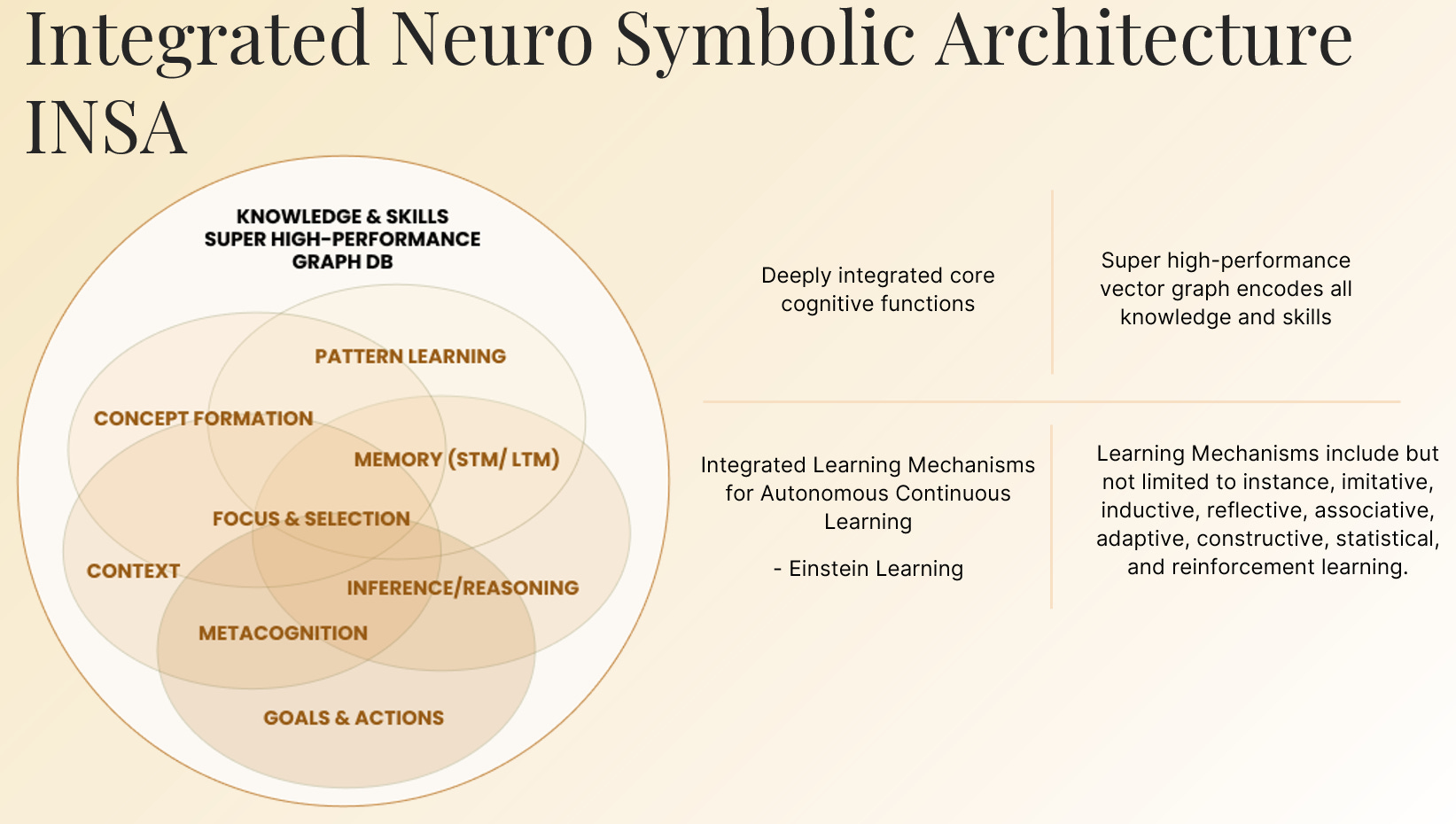
INSA makes this loop tight and coherent, to deliver real intelligence, a system that adapts in real-time, in the real world, learning incrementally from continuous inputs, consuming orders-of-magnitude less data and compute because it reuses structure instead of relearning every frame. Hallucinations never “vanish by scale” but they disappear in INSA because semantics are grounded in a shared, evolving model, not just surface correlations. That’s the new electricity, powering every individual, every company and every country.
Once available, this real intelligence becomes upstream of every scientific discovery, every technological innovation, delivering radical abundance and elevating human flourishing at scale without having to mindlessly burn the planet for a prompt, preserves personal autonomy & privacy, offers highly-personalized services in every walk of human life, significantly enhancing human experience, engagement, problem-solving ability, and the overall well-being for everyone in a very pragmatic way, at global scale.
That’s the mission: build real intelligence, AGI, so our generation is the one that gets it right and positively changes the world for good.
As Elon Musk put it, “When something is important enough, you do it even if the odds are not in your favor.” The odds are stacked against us not by nature but by incumbents - powerful, mighty, and married to a failed paradigm.
Bottom line:
You don’t assemble intelligence from parts at the end. You design the cognitive engine with real-time incremental learning as the driver, so the parts co-evolve from the start. Until then, it’s gorgeous video, clever demos and a very expensive, $10T mirage.
Dig Deeper:
No one will "get there" without an automated method to acquire knowledge. Human in the loop has failed from CYC (40 years $250 m) to the deprecated Watson-Health (5 years $2 b). Your Cognitive AI papers point to the problem. How does it solve the problem of loading data or process to create a real world view that is machine active. An example is in this post regarding how a Semantic AI model (SAM) in the W3C RDF Berners-Lee world view Web 3.0.
http://aicyc.org/2025/09/16/extending-sam-to-handle-causality-with-do-calculus/