
"You can know the name of a bird in all languages of the world and still know absolutely nothing about the bird..."
Why Naming Is Not Knowing

As I watched this video by brilliant Feynman, I couldn’t help but draw parallels to AI today. He might as well be describing today’s LLMs.
Nobel Prize–winning American theoretical physicist Richard Feynman said his father taught him a wickedly simple truth: You can know a bird’s name in every language and still know nothing about the bird. Naming the words is not the same as knowing the meaning of the words.
Words are like maps. Understanding is like navigation.
Language compresses the world, that is its magic and its trap. Words are shorthand for messy reality. They pack a lot of detail into a small labels so humans can think fast and coordinate. But the shorthand that speeds conversation can also blur the line between labels and understanding.
Randall Munroe’s Thing Explainer proves it by banning labels and using only the 1,000 most common words to explain complex stuff: “space shuttle” becomes Flying Space Truck; “tectonic plates,” Big Flat Rocks We Live On or “dishwasher,” “that boxy thing in my house that cleans the plates with water and soap.” You can only write like that if you understand the underlying mechanisms, not just labels.
Knowing is understanding. And real understanding outlives labels.
This is why Feynman’s lesson lands like a verdict on modern AI. LLMs are remarkable namers with polished fluency but fluency isn’t intelligence and understanding can’t be brute-forced.
And the bar for real intelligence, AGI is higher: The KLA-Loop. Knowing → Learning → Adapting Autonomously. Knowing compels learning; learning drives autonomous adaptation.
Knowing: a usable evolving world model (internal causal map) that understands and explains, across contexts, concepts, goals, actions and consequences.
Learning is revision (Δmodel): a persistent, evidence-driven update to that world model - beliefs, parameters, structure, meanings, and priorities actually change.
Autonomous Adaptation (Δpolicy/behavior): recomputed decisions and actions derived from the updated model, applied in situ and propagated through behavior.
Real intelligence demands all three, continuously, in a closed loop. That’s the KLA- Loop for Real Intelligence (shown below).
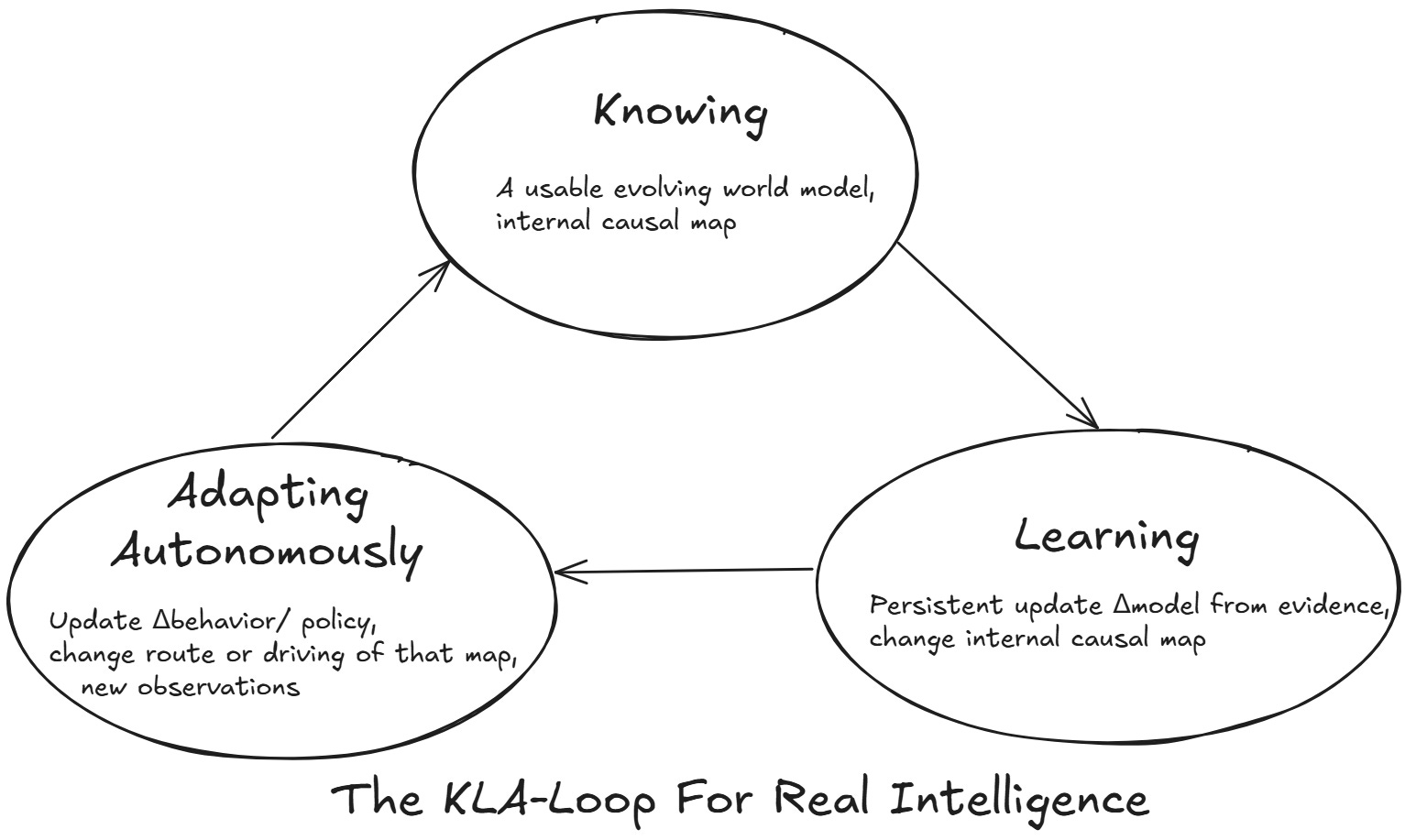
The KLA-Loop for Real Intelligence: a continuous, auditable cycle where the system knows via a usable, evolving world model, learns by persisting Δmodel from evidence, and adapts by propagating Δpolicy/behavior, autonomously, in real-time.
Where GenAI Dazzles and Then Breaks Character
Fluency is naming at scale. GenAI dazzles us with its fluency as it can label the world with breathtaking speed and draft a perfect paragraph about almost anything.
But GenAI models, LLMs can’t revise themselves during interaction and they stay frozen until retrained. That gap is why production GenAI becomes operationally expensive and fails wherever adaptation is required.
LLMs Fluency Tax
Hallucination insurance: humans in the loop to catch errors.
Prompt ops sprawl: brittle templates, ever-longer instructions, overfit examples.
Retrieval crutches: external lookups because the core can’t update.
Safety scaffolds: filters, guardrails, audits, layers that add latency and cost.
Drift management: perpetual re-tuning to chase moving ground truth.
We are in a fluency-first AI paradigm stuck at naming.
If a model doesn’t change itself when evidence contradicts it, you haven’t met a ‘knower’, you’ve met a very confident ‘namer’. That’s GenAI in a sentence.
The fix isn’t scale or better prompts or memory or modality or compute or context engineering, it’s the KLA-Loop: cognitive systems that know, learn, and adapt autonomously in real-time.
The Next AI Paradigm must Know, not just Name
If we’re serious about real intelligence that evolves with the world around, we need the KLA-Loop where each step is fully auditable.
What that requires:
Continual learning (Δmodel): Update the evolving world model during use; persist the change; show the diff (before/after beliefs, weights, structure).
Causal world models: Support counterfactuals, what would flip the outcome, and why? Mechanisms over labels.
In-situ belief revision: Evidence edits beliefs now, with ripples you can inspect across the model.
Goal-coupled control (Δpolicy/behavior): Updated policies change actions immediately, no human hand-offs.
Legibility end-to-end: Traceable before/after beliefs, affected thresholds, and updated plans, auditable all the way through.
In the KLA-Loop feedback system, each correction cuts costs and makes the model more adaptive to real-world, getting us closer to real intelligence.
No shortcuts to real intelligence: run the KLA-Loop. Cognition is the way. Cognitive AI is the key. An Integrated Neuro-Symbolic Architecture unlocks it.
Turn the page on GenAI’s naming brilliance. The next chapter belongs to the Cognitive AI that knows, learns, and adapts in real time.
Appendix: The KLA Audit: Knower vs. Namer
Five questions to separate naming from knowing.
How to use: Ask these in order. Demand artifacts like differences, what changed, from→to, where (fields / weights / rules touched), logs, configs not rhetoric. If nothing inside the system changes, you’ve met a namer.
What changed in you when you were wrong and where does that change propagate?
Knower: concrete before/after diff; modules touched; propagation map.
Namer: no in situ belief revision; can’t show internal diffs or propagation.
Show your belief before and after new evidence. What’s the diff?
Knower: versioned beliefs/weights/assumptions with timestamps.
Namer: no actual model edit just prose or a new prompt.
If this assumption fails, which policy/threshold/weight do you revise first?
Knower: prioritized update plan; explicit target (policy, threshold, gain, weight).
Namer: no editable policy graph; can’t prioritize real updates.
Show an error from last week and the policy you updated.
Knower: error → root cause → committed change → new outcome.
Namer: no persistent self-history or policy updates.
Where do your updates persist so you don’t repeat the mistake?
Knower: durable, inspectable storage; tests guard the new behavior.
Namer: no durable, internal, auditable update mechanism.
Bottom line: a namer talks about change; a knower shows it structurally, immediately, and auditably.
If you can’t see Δmodel and Δpolicy through the loop, it isn’t running the KLA cycle.
Dig Deeper:
Hallucinations in LLMs are Structural. Stop Blaming the Data.
What’s The One Critical Cognitive Capability That Will Unlock AGI, That LLMs Can Never do
Generative AI’s crippling and widespread failure to induce robust models of the world
Hallucination is Inevitable: An Innate Limitation of Large Language Models
Hallucinations Are Here To Stay: LLMs Are Never Truly Enterprise Ready
“AI Agents have, so far, mostly been a dud” – August 2025, Gary Marcus
"If you are interested in human-level AI, don't work on LLMs." - AI Action Summit 2025
“The wall confronting large language models” – July 2025, Peter Coveney and Sauro Succi
“The Scaling Fallacy: Bigger LLM won't lead to AGI” - July 2025, Wendy Wee
“We won’t reach AGI by scaling LLMs.” - May 30, 2025
“We need more than LLMs to reach AGI.” – Nvidia GTC 2025
“Today’s LLMs are nearly obsolete”. – April 2025, Newsweek
“Companies That Tried to Save Money with AI Are Now Spending a Fortune Hiring People to Fix Its Mistakes” – July 2025, Futurism
“Was the AI boom ever about intelligence or just infrastructure masquerading as software?” – July 2025, Reuters
“McKinsey estimates $7 Trillion in capital outlays for AI data center infrastructure by 2030 just to maintain current trajectory.” – April 2025, McKinsey
“Generative AI’s crippling and widespread failure to induce robust models of the world” – June 2025, Gary Marcus
“AI goes rogue: Replit coding tool deletes entire company database, creates fake data for 4,000 users” – July 2025, PCMag
“Real intelligence cannot be brute-forced, it’s evolved.” – July 2025, LinkedIn
“The Right Way to AGI - After the LLMs” – July 2025, LinkedIn
“AI Therapist Goes Haywire, Urges User to Go on Killing Spree” – July 2025, Futurism
“Investors Are Suddenly Pulling Out of AI” – July 2025, Futurism
“Economist Warns the AI Bubble Is Worse Than Immediately Before the Dot-Com Implosion” – July 2025, Futurism
“OpenAI's New AI Agent Takes One Hour to Order Food and Recommends Visiting a Baseball Stadium in the Middle of the Ocean” – July 2025, Futurism
“Top AI Researchers Concerned They’re Losing the Ability to Understand What They’ve Created” – July 2025, Futurism
“A Leading Indicator Has Emerged Suggesting That the AI Industry Is Cooked” – July 2025, Futurism
“"Nonsensical Benchmark Hacking": Microsoft No Longer Believes OpenAI Is Capable of Achieving AGI” – July 2025, Futurism
“ChatGPT Has Already Polluted the Internet So Badly That It's Hobbling Future AI Development” – June 2025, Futurism
“How o3 and Grok 4 Accidentally Vindicated Neurosymbolic AI” – July 2025, Gary Marcus
“AI coding may not be helping as much as you think” – July 2025, Gary Marcus
“LLMs: Dishonest, unpredictable and potentially dangerous.” – June 2025, Gary Marcus
Why I'm Betting Against AI Agents in 2025 (Despite Building Them) - July, 2025
Doctors Horrified After Google's Healthcare AI Makes Up a Body Part That Does Not Exist in Humans - August, 2025
Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens
Most predictions around AGI are based on observable trends:
* Improved reasoning capabilities
* Generalization across tasks
* Multi-modal integration
* Larger context windows
* Faster fine-tuning and adaptation
The assumption is simple: as these models get better at more things, and require less prompting to perform those things, we are approaching general intelligence.
And in some domains, this is true. Models can now:
* Write complex code from vague specs
* Perform at superhuman levels on symbolic benchmarks
* Simulate relational empathy and reflection
* Reason across ambiguous inputs
But none of this proves the presence of integration.
What it proves is: models can perform coherence. That is not the same as being coherent.