
What Leapfrogs LLMs and Starts The Next Wave of AI?
Look closely, the unlock is already here.

From Scale-First to Adaptation-First
For the past decade, the AI field largely operated on the scaling thesis: feed models more data, more parameters, more compute, more power and intelligence would emerge, with trillions at the end of the rainbow. That scale-first strategy delivered impressive systems: useful, fluent, broadly applicable. Yet as models grow, headlines now echo what insiders have said quietly for months: something essential isn’t arriving with scale alone.
Asked whether GPT-5 meets the bar for AGI, OpenAI CEO Sam Altman put it plainly: “We’re still missing something.” He then named it, continuous learning: “One big one is, this is not a model that continuously learns as it’s deployed from the new things it finds, which is something that to me feels like AGI.”
Elon Musk, meanwhile, responded with “💯” when someone raised the criticality of learning and updating the model in real-time, a tacit admission that what matters next isn’t just more scale. Together, these remarks coming from the two of the most popular and loudest champions of the scale-first paradigm saying the quiet part out loud, the takeaway is unmistakable: the next leap won’t come from size alone.
Yet even as they admit what’s missing, the GenAI giants default to scaling, struggle with true continual learning and charge blindfolded into ever-larger training runs. Maybe too deep or too hard to pivot, don’t expect to hear this in their keynotes or podcasts.
LLMs remain useful tools under human supervision for language interaction, retrieval, summarization, coding assistance, and interface orchestration. But the returns from pure scaling are flattening, while costs in energy, latency, and operational complexity continue to rise. Two new research papers underline the plateau: LLMs Scaling laws hit a hidden wall of compute and reasoning mirage.
The Compute Wall: Fixing error rates by one order of magnitude = 1020 more compute practically requiring a galaxy-sized solar farm. But the problem isn’t just inefficiency, it’s instability. As LLMs scale they become degenerative accumulating more runway errors, hallucinated facts, and brittle outputs masked by surface-level fluency. These aren't edge cases they're structural failures exacerbated by scale.
Chains of thought ≠ Reasoning: Chains of thought fail to generalize. The reasoning steps often don’t align with outcomes, and vice versa, what looks like reasoning is mostly the simulation of reasoning-like text. In short, LLMs aren’t principled reasoners; they’re pattern replicators.
But there’s more fundamental reason why LLMs cannot learn and update their model during use: LLMs aren’t built to be adaptive, cognitive, or autonomous. Once trained LLMs are frozen between retrains, no metacognitive control over what/when/why to learn. There is no mechanism to revise static content and propagate new insights coherently throughout the model. Patches like RAG, fine-tunes, and guardrails may help, but they can’t let LLMs revise themselves while they operate. This isn’t a missing feature; it’s a hard architectural limit and it demands a new architecture. So what’s missing is not a “bigger” model with more data, compute or energy, it’s adaptive and self-directed architecture.
It’s what DARPA calls “The Third Wave of AI” - Cognitive AI built on Integrated Neuro-Symbolic Architecture (INSA) that:
uses many orders of magnitude less data and compute, and
doesn’t suffer the inherent limitations of LLMs such as hallucinations, lack of reliability, constant need for a human in the loop, and most importantly
learns (updates itself) incrementally in real time.
Cognitive AI thus moves us from a Scale-First to an Adaptation-First AI era - autonomous and adaptive in real-time.
Define the Target: Real Intelligence, Operationally
A practical definition guides the path forward:
Real intelligence is the ability to continuously acquire and apply knowledge and skills across diverse and novel contexts, updating beliefs, behaviors, and understanding in real-time.
LLMs by design cannot ever achieve this as it requires systems that improve in real-time, not just before deployment. Real intelligence isn’t just pretrained or retrained, it evolves continuously.
What’s Actually Missing?
The missing ingredient isn’t cleverness, scale, guardrails, or retrieval hacks. The missing capability is incremental learning. With Incremental Learning the system in real-time chooses:
What to learn: identifying knowledge gaps and seek high-value new knowledge.
When to learn: choose to explore new knowledge or exploit what’s known.
Why to learn: aligning effort with internal priorities and goals.
How to apply it: integrating new insights into behavior, beliefs and actions.
At that moment, the pretraining and retraining factory closes. No full-model reprocessing, no GPU farms spun up to patch a memory hole, no petabytes of scraped data, no power-plant budgets.
AGI Pioneer
reiterated the criticality of ‘Incremental Learning’ in a 2024 white paper: If an AI can’t learn incrementally, it’s not on the AGI path.‘Incremental Learning’ collapses the GenAI infrastructure bloat.
‘Incremental Learning’ is the single AI capability that rewrites everything.
The Adaptive Core: Cognitive AI with INSA
Cognitive AI is an approach that pulls together all the core cognitive functions of human intelligence that allow us to navigate, and address a wide range of problems in the real world. Cognitive AI accomplishes this using an Integrated Neuro-Symbolic Architecture (INSA) at its core that makes Cognitive AI adaptive by design.
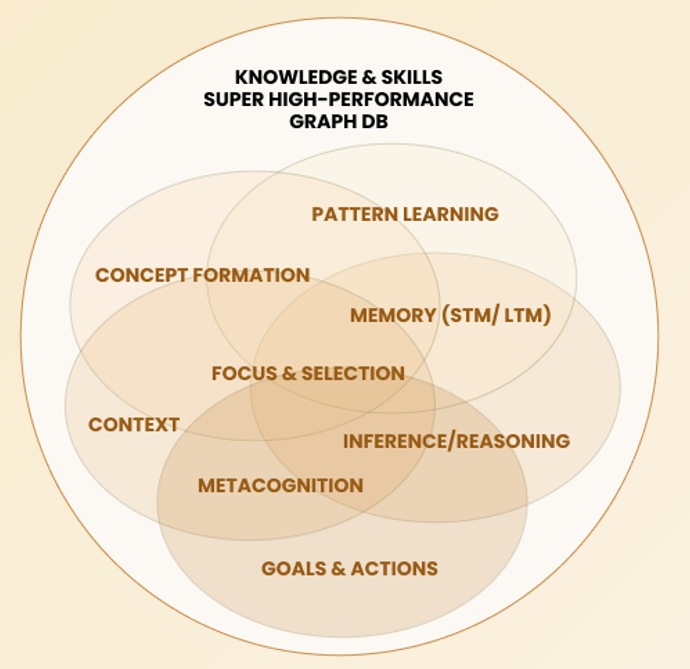
INSA deeply integrates all core cognitive functions of human mind. INSA’s core substrate is an ultra-high-performance vector graph database which encodes all of the system’s knowledge and skills. This knowledge graph is custom designed for this architecture and is 1000 times faster than any commercially available graph database.
INSA enables Cognitive AI to learn like humans, scale like machines.
INSA gives Cognitive AI the one capability GenAI giants keep naming yet still struggle to deliver: incremental, continual, adaptive, real-time, and self-directed learning.
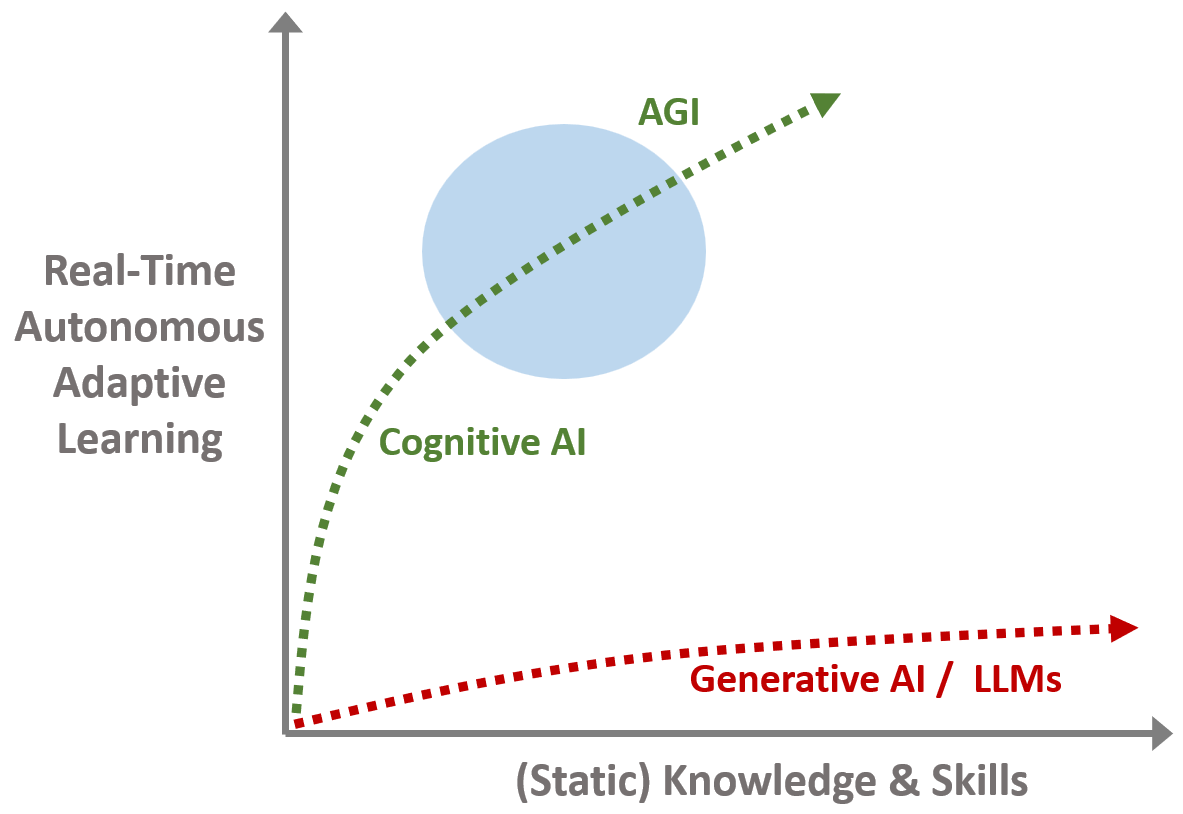
Incremental learning enables Cognitive AI to deliver real intelligence, AGI.
With incremental learning, the system behaves like a mind. It learns the way we do: incrementally, contextually, continuously. It adapts. It grows. It self-corrects with orders of magnitude ( a million times) less data and compute.
It runs on off-the-shelf hardware. It preserves privacy by learning locally. It keeps improving autonomously. It doesn’t hallucinate because it knows what it knows and revises what it doesn’t. It manages its own data quality, it reasons, reflects, and remembers.
It doesn’t need to eat the whole internet to evolve, it consumes only what matters, when it matters and knows why.
Software ate the world; cognition will rebuild it.
Static programs gave us scale. Systems that learn in real-time powered by an integrated neuro-symbolic core will give us adaptation, reliability, and a compounding curve.
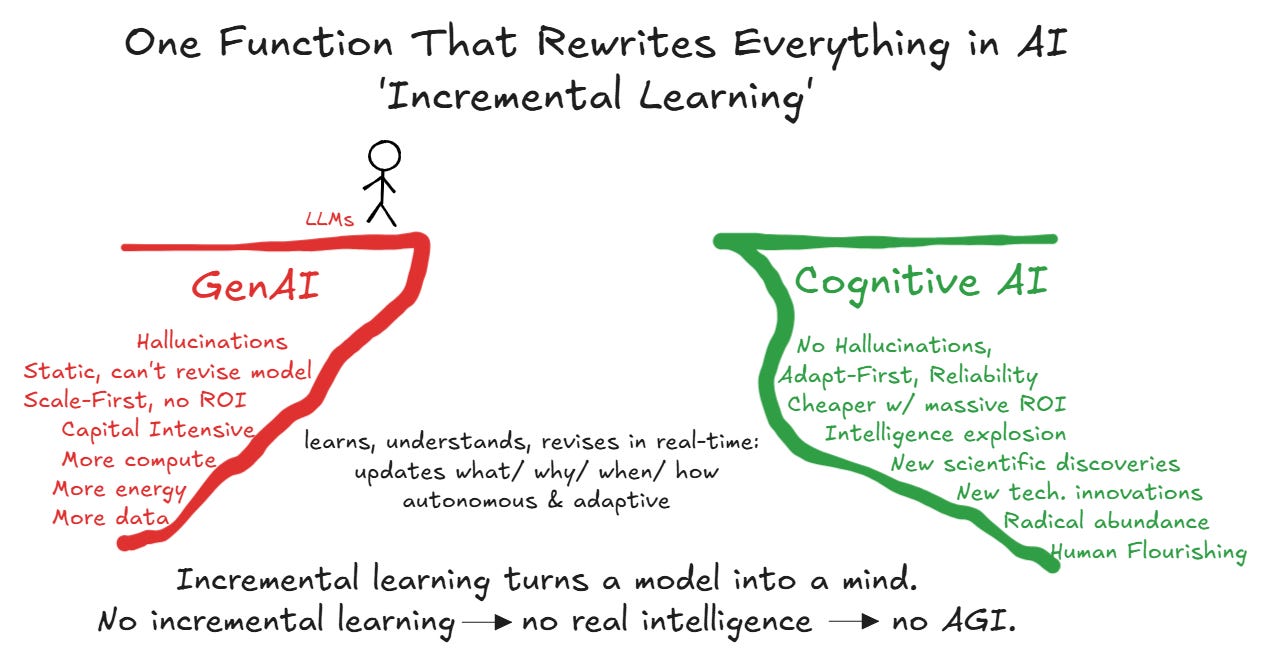
No AI system crosses the canyon without ‘incremental learning’.
Let’s also be clear that continuous learning isn’t continuous ingestion of data.
This is not fire-hosing more web data at inference. Unless a system self-selects what to study and updates internal representations, you’re just caching answers. Worse, live ingestion without metacognitive gates invites poisoning and prompt-injection.
A system like that rewires itself on the fly, every new insight ripples through its concept maps, updating beliefs, behaviors, and priorities with full awareness of implications. That’s not a plugin, not a patch, it’s the foundation of a new paradigm.
The new foundation is Cognitive AI with Integrated Neuro-Symbolic Architecture (INSA) at its core, delivers Real Intelligence, AGI.
The LLM boom was the warm-up act: it gave the world a taste of synthetic fluency and exposed the limits of scale. What’s next isn’t more of the same, but adaptive systems that evolve autonomously through interaction and reflection.
GenAI was the spark. Cognitive AI is the fire.
With Cognitive AI that learns incrementally, powered by a neuro-symbolic core the pieces finally click: fewer tokens, less compute and energy, higher reliability, and a direct path to what matters: new science, new technology, radical abundance, and human flourishing.
As we move from static fluency to adaptive cognition, value accelerates and the unlock is already here.
Real intelligence begins.
Dig Deeper:
Cloudn't agree more, you frames something I’ve been thinking also: intelligence without integration is brittle. Scaling LLMs has given us fluency, but fluency without the ability to revise, metabolize, and return to coherence is exactly why they plateau.
In my practice, I’ve seen how even humans falter here: systems fail not because we don’t understand integration, but because we don’t build structures that hold it under pressure. AI is no different. Continuous or incremental learning isn’t just a technical unlock, it’s the architectural move that turns output machines into systems that can sustain alignment over time.
That’s why I find the “Adaptation-First” framing so important. It’s not only about machines that learn in real-time, it’s about whether we design systems, human or technical, that can metabolize contradiction without collapse.