
Continuous Learning In LLMs Is An Oxymoron
Learning Architecture Wins the AI Era. Not Frozen Models. Not Data. Not Compute. Not Energy.

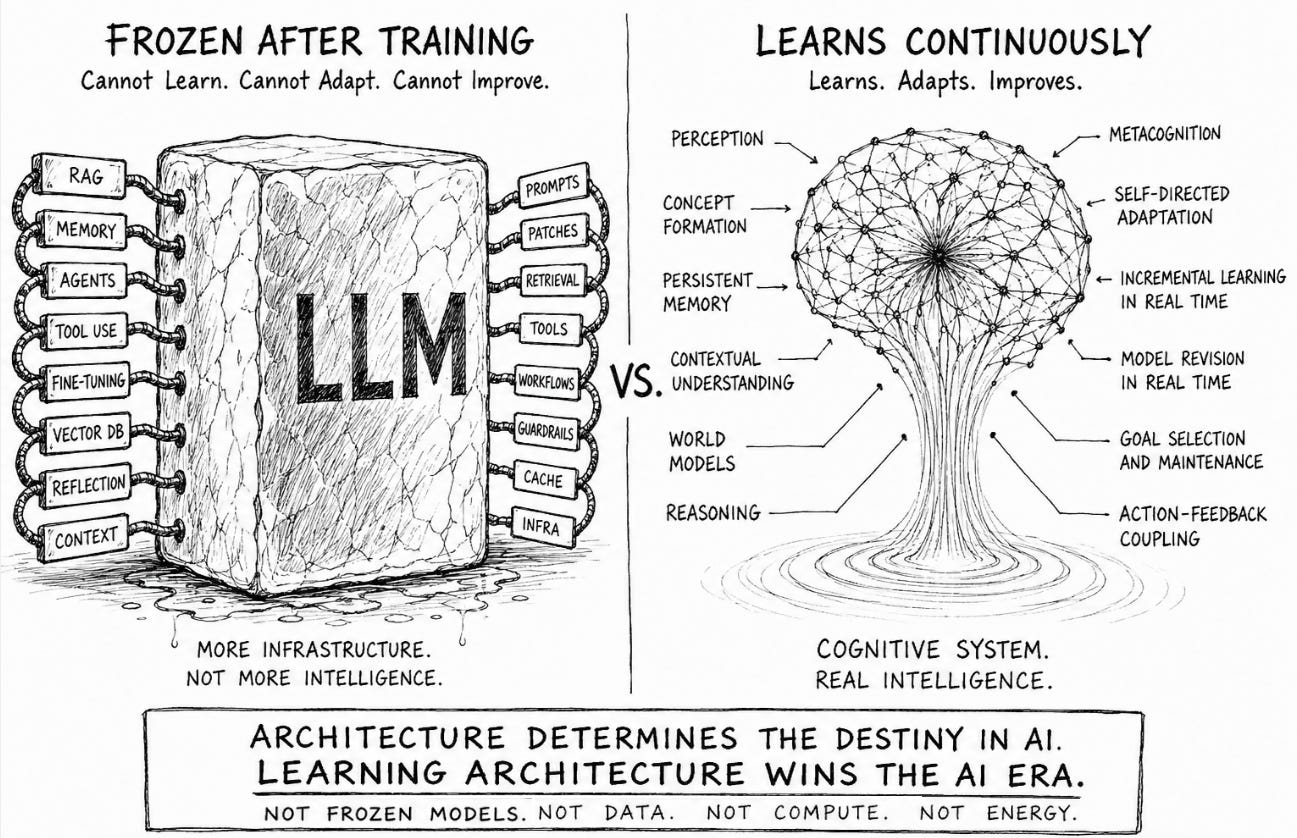
The moment continuous learning enters the AI conversation, frontier labs immediately claim they are already solving it with LLMs by attaching memory layers, vector databases, agents, reflection loops, or retrieval systems to frozen models. None of these transform a frozen statistical predictive engine into a continuously learning cognitive system.
The phrase itself collapses under technical scrutiny because transformer architectures were never designed for autonomous, persistent, incremental adaptation in production environments. They were designed for large-scale statistical compression followed by inference over frozen weights.
That distinction exposes the core illusion underneath Generative AI.
Before explaining why transformer systems fundamentally break under continuous learning, we first need to define what real “Continuous Learning” actually means because the AI industry quietly redefined the term to protect the narrative.
Continuous learning is not periodic retraining, not fine-tuning, not injecting temporary context into a prompt window, and not storing embeddings in a vector database.
Real continuous learning means the system itself changes persistently through experience while operating. That requires a fundamentally different kind of architecture: a learning architecture.
A true learning architecture must learn incrementally, in real time, from single examples, across modalities, under incomplete and noisy real-world conditions. It must integrate new knowledge across concepts, memory, and behavior without destabilizing what it already knows. It must recognize uncertainty, seek missing information, revise itself autonomously, and use metacognition to understand what it knows, what it does not know, what to update, and why.
Metacognition changes the entire equation because it becomes the system’s internal verification and self-regulation mechanism.
A continuously learning system requires metacognition: the ability to monitor, regulate, revise, verify, and improve its own internal models while preserving coherence, memory, goals, reasoning stability, and contextual understanding over time.
Transformer architectures fundamentally struggle here because they were never designed for persistent, real-time cognitive adaptation.
LLMs do not learn while operating. They do not accumulate experience the way biological or cognitive systems do. They do not build persistent causal understanding from interaction with the world. Once training stops, the statistical intelligence encoded inside the model stops evolving because the system itself becomes structurally resistant to modification.
The problem begins with how transformers store knowledge. Knowledge inside an LLM is not organized into stable concepts, explicit abstractions, causal structures, or persistent world models. It exists as distributed statistical correlations smeared across billions or trillions of parameters optimized through gradient descent. The model does not “understand” a concept in the human sense. It compresses statistical regularities into latent probability spaces that allow plausible token prediction.
That compression mechanism is precisely why continuous learning breaks the system.
When new information is introduced through gradient updates, the model cannot isolate learning cleanly because representations inside the network overlap massively. Updating one capability perturbs countless unrelated regions of the parameter space because the architecture entangles knowledge globally. The result is catastrophic forgetting, representational drift, instability, degraded reasoning, and unpredictable behavior changes across previously learned domains. The more generalized the model becomes, the more dangerous incremental modification becomes because the entire system depends upon fragile statistical equilibrium across compressed distributed representations.
This is not a temporary engineering limitation waiting for larger clusters or better optimizers. This is a direct consequence of transformer architecture itself.
Continuous learning demands plasticity while large-scale language generation demands stability.
Those objectives fundamentally conflict inside dense transformer systems. That conflict explains why the industry quietly redefined the word “learning” to protect the narrative.
Without continuous learning, LLMs remain trapped in the same loop: generate, retrieve, retrain, repeat, somewhat useful, expensive, but architecturally incapable to ever deliver real intelligence.
Fine-tuning is now marketed as learning even though it remains episodic offline retraining requiring curated datasets, GPU clusters, human supervision, optimization cycles, evaluation pipelines, safety re-alignment, deployment orchestration, and repeated infrastructure expenditure. That is not learning in any biologically meaningful or cognitively meaningful sense. It is scheduled software patching at industrial scale. When humans learn, internal models change persistently across perception, understanding, assumptions, reasoning, behavior, and action. LLMs do not update this way while operating.
The model itself remains fundamentally frozen between retraining cycles.
Humans do not stop functioning every quarter to retrain on terabytes of life experience before regaining operational capability. Biological intelligence updates incrementally, continuously, contextually, and autonomously during interaction with the environment itself. The learning process is inseparable from operation.
LLMs cannot do this because their architecture was never built for it.
The industry response has been to construct increasingly elaborate scaffolding around frozen models while pretending the scaffolding itself constitutes intelligence.
Retrieval-Augmented Generation, vector databases, memory layers, agents, tool-use frameworks, orchestration systems, and reflection loops are all attempts to compensate for the inability of the core model to evolve persistently through experience. None of these mechanisms solve continuous learning because none of them modify the underlying cognitive structure of the model itself.
Retrieval is not learning.
This is also why LLMs appear strongest in software development. Code exists inside a tightly bounded verification environment with compilers, tests, syntax constraints, rapid feedback loops, and deterministic evaluation. The surrounding infrastructure continuously stabilizes the model’s outputs. That enables recursive automation inside software workflows without requiring genuine autonomous cognition. Reality outside software is far less forgiving.
Injecting external context into a prompt window does not create internal understanding, persistent adaptation, causal abstraction, or autonomous model revision. The model remains fundamentally unchanged while temporary information is fed into inference time conditioning. Once the session ends, the “learning” disappears because nothing durable was formed internally. The architecture remains frozen while external infrastructure simulates flexibility around it.
This is why the current AI stack increasingly resembles a prosthetics industry built around frozen statistical cores.
The deeper technical issue underneath all of this is the stability-plasticity dilemma, one of the oldest unsolved problems in neural computation. Any intelligent system capable of continuous adaptation must preserve prior knowledge while remaining flexible enough to integrate new knowledge without destabilizing existing capabilities. Biological cognition solves this through layered memory systems, sparse activation, contextual retrieval, episodic memory, semantic abstraction, procedural learning, attention gating, and continual memory consolidation processes operating across multiple timescales.
Transformers solve none of these problems, not natively.
Everything is compressed into a dense parameter field optimized for probabilistic token prediction. Learning new information therefore risks globally perturbing prior representations because the architecture lacks stable modular cognitive organization. The irony is brutal: the more researchers pursue continual learning in transformers, the more they avoid touching the actual model itself.
Frozen cores, replay systems, adapter layers, synthetic rehearsal datasets, external memory modules, parameter isolation strategies, and auxiliary networks increasingly dominate continual learning research because directly modifying the core transformer destabilizes the system.
The architecture itself is clearly signaling the limitation.
Real continuous learning requires something entirely different from statistical next-token prediction. It requires a cognitive architecture built around persistent structured memory, incremental online adaptation, stable concept formation, causal world modeling, metacognition, autonomous goal-directed interaction, memory consolidation, and contextual reasoning mechanisms capable of evolving without catastrophic interference. Intelligence does not emerge from compressing more internet text into larger statistical manifolds. Intelligence emerges from architectures capable of continuously restructuring internal models through interaction with reality itself.
This is where the current AI narrative falls apart.
Scaling or layering does not solve this problem because they amplify the same underlying instability dynamics. Larger models contain more entangled representations, require larger retraining cycles, consume more infrastructure, increase synchronization complexity, and compound operational cost while preserving the same frozen learning paradigm underneath. Scaling improves interpolation power across known statistical distributions. It does not magically produce autonomous cognition, persistent learning, or causal understanding.
The economic implications are enormous because the inability to continuously learn traps the industry inside perpetual retraining cycles. Models must constantly be refreshed, re-aligned, re-optimized, and re-deployed at planetary infrastructure scale simply to remain commercially competitive. The result is exploding compute demand, accelerating energy consumption, escalating infrastructure debt, and increasingly fragile economics disguised as technological inevitability.
This is infrastructure compounding, not intelligence. No wonder they’re spending trillions building nuclear plants, power grids, 100s of datacenters, compute etc.
The real fault line emerging in AI is no longer open versus closed models, large versus small models, or multimodal versus unimodal systems. The real divide is between frozen statistical prediction engines and continuously learning cognitive systems.
The future of AI will not be determined by who compresses the most internet data into the largest statistical model. It will be determined by who builds architectures capable of learning continuously, adapting autonomously, and compounding intelligence through experience itself.
One path leads to perpetual retraining, infrastructure escalation, and a dead end for real intelligence. The other delivers real intelligence by consuming minimal resources.
That is the architectural divide defining the next era of AI.