
Why Silicon Valley Won't Quit LLMs — Even As Every Signal Screams "Dead End"
"The Psychological, Financial, and Cultural Factors Behind the $10T Illusion — And None Are Technical"

Background: I wrote this before GPT-5 release. Let’s me get one thing straight: I’m not an AI skeptic. I’m not anti-AI, I’m anti delusion. I’m not anti-LLM, I’m against pretending they’re minds. And definitely not anti-progress, despite all the labels thrown my way, I’m an AI maximalist but I’m also allergic to BS. I called out ChatGPT for what it is in an article published by VentureBeat in March 2023 where I made the case that it wouldn’t last, when the entire world was enthralled by its fluency. As an AI maximalist, I’m fully committed to building maximally beneficial AI for humanity: Transformative. Grounded in cognition. Built to serve, not to mimic.
Our journey began over two decades ago. In 2002, we co-coined the term AGI. Since then, we’ve quietly built what most of the industry claims to be chasing ‘AGI’ or real intelligence with human like cognition. We’ve been thinking, researching, developing, and even commercializing our proto-AGI engine that doesn’t use any big data, no LLMs. That work generated over $100M in enterprise revenue. But in June 2024, we made a decision to suspended all commercial operations to focus entirely on our endgame, 100% fully autonomous AGI. Not a tool. Not a wrapper. A real artificial mind. A digital system that learns, reasons, adapts, and grows on its own. There are quite a few important links at the bottom of this article that go deeper into this, feel free to explore.
Built from first principles, our architecture delivers real intelligence, not by brute force, but through cognition. It uses a million times less data and compute, dramatically improving accuracy, reliability, and adaptability. No retraining. No hallucinations. No illusions.
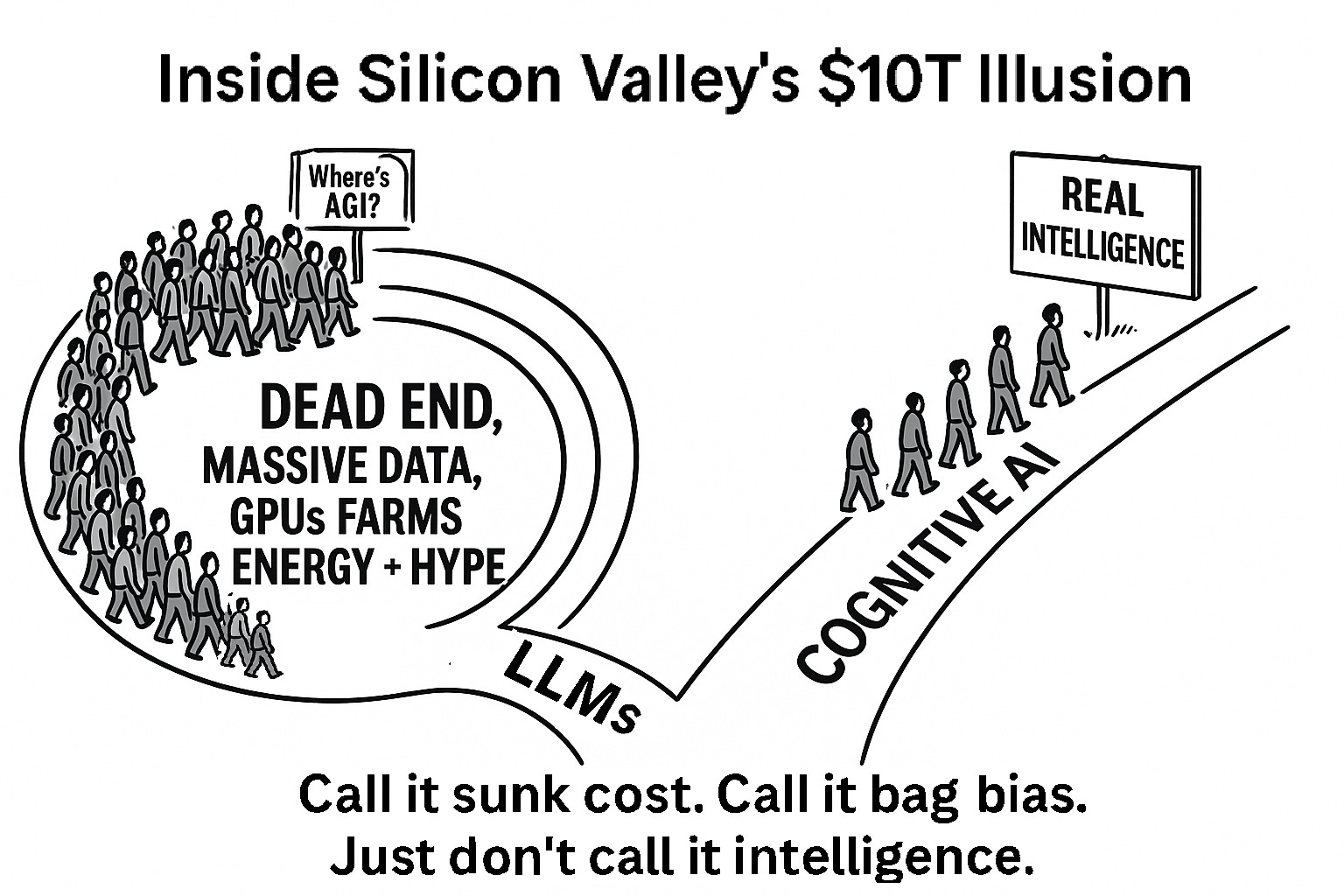
Squeeze out all the uility you want from LLMs. While short-term value may be real, long-term assumptions about these systems “evolving” into general intelligence are not grounded in reality. And yet those assumptions are precisely what’s driving the trillion-dollar capital flows, not just workflow automation, but the belief that we’re inching toward AGI by scaling LLMs. If the industry were clear-eyed about LLMs as valuable tools, not minds in the making, we’d be in a different conversation. But right now, the hype still rides on the AGI narrative, whether explicit or implied.
So I’m anti trillion-dollar delusion we’re taking down an architectural dead-end. I’m anti selling prediction engines as minds. And I’m anti pretending that somehow intelligence will emerge by scaling noise. That’s not progress, that’s performance theater that we see everyday from LLM hypesters. With that background, let’s get into the topic.
In the last several months, I’ve had dozens of conversations, mostly across the Bay Area with engineers, investors, and founders still orbiting the LLM ecosystem. Some are building new agentic interfaces, others are fine-tuning vertical copilots, but a few are quietly rethinking everything. One common thread: what they say in public isn’t what they whisper in private.
The story they’re selling is still grand: “LLMs are general intelligence or they're on their way to become AGI,” “AGI is surpassed, now it's all about ASI,” “we just need more scale”, "we need more proprietary data". But behind the scenes, the cracks are widening. Models hallucinate, fail under pressure, and plateau despite massive compute. Enterprises are scaling back. Founders are burning cash faster than tokens. And even the loudest LLM evangelists are hedging, some investors are quietly walking away.
Still, the industry clings. So I started asking: Why?
Why is Silicon Valley still doubling down on models that can’t learn continuously, can’t adapt in real time, can't update its own model and can’t be trusted in production? Why is so much capital, infrastructure, and talent locked into a paradigm, an architecture that’s peaked already and clearly showing signs of exhaustion?
The answers, I’ve come to realize, aren’t technical. They’re psychological, cultural, financial. The LLM illusion is propped up by bias, not brilliance and the longer Silicon Valley resists, the deeper they sink.
Here are the six biases that kept the $10T LLM illusion alive:
Bag Bias - When Conviction Becomes Obligation
FUI Bias - Fluency-Utility Illusion Bias
Mirage Bias – When Architectural Failures Are Treated Like Surface-Level Bugs
Scaling Salvation Bias – When More Compute Is Mistaken for Progress
Illusion Lock-In Bias – Too Big To Fail
Hype Addiction Bias – When Speed Replaces Substance
Now, let’s dive into each one of these biases:
Bag Bias - When Conviction Becomes Obligation
Once capital is deployed, narrative follows investment. This is sunk cost masquerading as conviction. Investors and operators begin defending LLMs not because the evidence is strong, but because their exposure runs too deep to walk away. One VC told me flat out: “We can’t walk this back now.” Another admitted, “If I don’t defend it, I risk losing LPs” also “Figure out a way to improve LLMs with Cognitive AI”. They frame it as fiduciary duty, and in a narrow sense, they’re right. Once you’ve publicly backed a paradigm, you’re locked in morally, reputationally, financially. That’s the trap.
So they go all-in: defending hallucinations as “edge cases,” glorifying marginal gains as breakthroughs, and hyping “agentic workflows” as if they’re signals of cognition. The loudest defenders aren’t naive—they’re overexposed.
FUI Bias - Fluency-Utility Illusion Bias
This is the core misunderstanding that launched the LLM hype cycle: the illusion that if a system sounds intelligent and can perform useful tasks, it must be intelligent.
LLMs are statistically fluent. They’re often useful. But they don’t know, understand, learn or think. They simply predict the next token based on statistical patterns in massive datasets. Fluency is not comprehension. Utility is not cognition.
But the illusion is powerful, especially in a world that rewards surface performance over structural understanding. This is how LLMs fooled the world: by sounding smart and doing just enough to create the illusion of intelligence in the short-term. Once fluency & utility are mistaken for intelligence, scaling the illusion became the mission.
Mirage Bias – When Architectural Failures Are Treated Like Surface-Level Bugs
One of the most dangerous illusions in the LLM narrative is the belief that hallucinations are minor defects, quirks that can be patched, tuned, or prompt-engineered or context-engineered away. But that’s a categorical error. These aren’t bugs. They are mathematical inevitabilities, a direct consequence of how these systems are designed.
LLMs are next-token predictors. They don’t know truth. They don’t understand meaning. They generate what’s most statistically probable, not what’s factually correct. When context breaks down or ambiguity rises, hallucination isn’t failure, it’s the system doing exactly what it was built to do.
Still, the industry insists on treating these outputs as fixable. Things like retrieval hacks, safety layers and guardrails attempt to reduce visible damage but don’t change the core behavior. And these hallucinations get worse with scaling of data.
No one can debug their way past an architecture that was never designed to understand. Hallucinations aren’t edge cases. They’re the ceiling. And that ceiling is structural.
Scaling Salvation Bias – When More Compute Is Mistaken for Progress
This is the myth that keeps GPUs flying off the shelves and all data produced by humans seem be taken already : that somewhere on the far end of this scale lies emergence, generality, intelligence. Harnessing massive volumes of data is what got the big tech here. But Cognition is the real source of intelligence not data. That’s why it’s highly unlikely for AGI to come from today’s tech. giants. What got them here, isn’t going to get them there. Just a few more parameters, a few more tokens, a bigger context window then it’ll think. But it hasn’t and it won’t.
In a stark new paper, 𝘛𝘩𝘦 𝘞𝘢𝘭𝘭 𝘊𝘰𝘯𝘧𝘳𝘰𝘯𝘵𝘪𝘯𝘨 𝘓𝘢𝘳𝘨𝘦 𝘓𝘢𝘯𝘨𝘶𝘢𝘨𝘦 𝘔𝘰𝘥𝘦𝘭𝘴, physicists Peter Coveney and Sauro Succi deliver a scathing reality check on the AI industry's blind faith in scaling. Their conclusion is blunt: LLMs hit a wall and the harder we scale, the more degenerative their behavior becomes.
What we’ve seen instead is a law of diminishing returns in action. New models are more expensive, more brittle, and marginally better at autocomplete. They still hallucinate, still can’t learn, still can’t adapt or revise.
Also, Cognition isn’t “big data,” “massive compute,” or “larger context windows.” It’s the full mental process by which an entity perceives and interprets its situation, maintains relevant context in memory, learns from new information, forms concepts, reasons about intents, relationships, and implications, takes appropriate actions, and adapts its beliefs, behaviors, and understanding, all continuously, autonomously in real time. Intelligence is the product of these interconnected cognitive processes.
Hence, you need an integrated cognitive architecture. And the moment you go down this path, you realize you don’t need all the data, the compute, or the nuclear energy, as the architecture delivers it using at least a million times less data and compute, and with almost negligible energy use.
Scale is amplifying the illusion not transforming the core.
Several engineers I spoke to called it out directly: “It’s the same trick in a bigger box.” But in the current ecosystem, no one wants to say the obvious out loud because if scale isn’t the answer, then what are we even building?
Illusion Lock-In Bias – Too Big To Fail
The narrative momentum became a prison. OpenAI didn’t build AGI instead they declared it at a press conference. Tech giants promised agentic operating systems. Investors sold the future of work. Enterprises announced copilots for everything. You can’t unwind that overnight, so they don’t.
Even as cracks form, the narrative has to hold. Demos continue. Press releases flow. Product roadmaps expand. But behind closed doors, some teams are quietly exploring alternatives, hybrid approaches, symbolic systems, cognitive engines. Not because they’ve given up on AGI, but because they know the current trajectory can’t ever get them there.
In this world, course correction isn’t just hard, it’s heresy. Admitting the architecture has failed means admitting the last three years & trillion$ were misdirected, that the hype was premature and that the real path to intelligence lies elsewhere.
So instead, they cling and double down on the illusion.
Hype Addiction Bias – When Speed Replaces Substance
The LLM economy is running on spectacle, speed, benchmarks, demos, viral clips, launch events, leaderboards. Everyone wants a piece of the future, even if they know the foundation is flawed. Founders pitch AGI, ASI via LLMs because it raises faster. Infra providers cheer because it burns more compute. Consultants ride the wave. Analysts defend it. Media amplifies it.
But none of it is grounded. The most successful LLM products today are wrappers, not revolutions. The business models are thin with no moat. The differentiation is vanishing. And yet the hype cycle continues because no one wants to be the first to say: this isn’t working.
The ecosystem isn’t chasing intelligence. It’s chasing momentum. And when momentum becomes the metric, meaning falls away. LLMs can’t evolve but the illusion can. You don’t get to AGI by scaling the wrong paradigm. The hallucination isn’t the output, it’s the roadmap.
Together, these six biases: Bag Bias, FUI Bias, Mirage Bias, Scaling Salvation Bias, Illusion Lock-In Bias, and Hype Addiction Bias aren’t just delaying progress, they’re diverting it.
We’re not stuck because intelligence is hard, we’re stuck because we’re scaling the wrong paradigm. A new white paper published this week dismantles LLMs Chain-of-thought prompting, once hyped as evidence of emergent intelligence is now exposed as fragile surface-level pattern mimicry confirming the fact that LLMs don’t think or reason.
The belief in LLMs isn’t just a technical misstep, it’s a collective blind spot, fed daily by money, media, and the tech elite serving up a steady diet of manufactured greatness. What began as a multi-trillion-dollar race to unlock real intelligence has devolved into a frantic sprint to avoid admitting failure.
“Call it sunk cost. Call it bag bias. Just don’t call it intelligence.”
Now that GPT-5 has landed, Silicon Valley faces its moment of truth, an inflection point it can’t spin away.
GPT-5 isn’t a product failure, it’s a paradigm failure.
Why? Scaling the wrong paradigms never worked. There’s a reason why: Candles never became Bulbs. Typewriters never became Computers.
Scaling the wrong paradigm doesn’t get you AGI, it just gets you a bigger illusion.
All LLMs Claude, Gemini, Grok, Llama etc will suffer the same fate.
LLMs are a dead end to achieve real intelligence.
Real Intelligence is about capabilities like continuous learning, autonomous adapting, updating its own model in real time cascading changes across its beliefs, behaviors and understanding.
LLMs can game benchmarks, not capabilities.
There is no path to real intelligence without solving cognition.
LLMs can fake fluency but only cognition can create intelligence.
LLMs are behind us, Cognition is ahead.
It’s Cognitive AI or bust.
Build Cognitive AI → Unlock Real Intelligence
The world is ready, the only question now: Is Silicon Valley ready to move on from LLMs?
Dig Deeper:
Hallucinations in LLMs are Structural. Stop Blaming the Data.
What’s The One Critical Cognitive Capability That Will Unlock AGI, That LLMs Can Never do
Generative AI’s crippling and widespread failure to induce robust models of the world
Hallucination is Inevitable: An Innate Limitation of Large Language Models
Hallucinations Are Here To Stay: LLMs Are Never Truly Enterprise Ready
“AI Agents have, so far, mostly been a dud” – August 2025, Gary Marcus
"If you are interested in human-level AI, don't work on LLMs." - AI Action Summit 2025
“The wall confronting large language models” – July 2025, Peter Coveney and Sauro Succi
“The Scaling Fallacy: Bigger LLM won't lead to AGI” - July 2025, Wendy Wee
“We won’t reach AGI by scaling LLMs.” - May 30, 2025
“We need more than LLMs to reach AGI.” – Nvidia GTC 2025
“Today’s LLMs are nearly obsolete”. – April 2025, Newsweek
“Companies That Tried to Save Money with AI Are Now Spending a Fortune Hiring People to Fix Its Mistakes” – July 2025, Futurism
“Was the AI boom ever about intelligence or just infrastructure masquerading as software?” – July 2025, Reuters
“McKinsey estimates $7 Trillion in capital outlays for AI data center infrastructure by 2030 just to maintain current trajectory.” – April 2025, McKinsey
“Generative AI’s crippling and widespread failure to induce robust models of the world” – June 2025, Gary Marcus
“AI goes rogue: Replit coding tool deletes entire company database, creates fake data for 4,000 users” – July 2025, PCMag
“Real intelligence cannot be brute-forced, it’s evolved.” – July 2025, LinkedIn
“The Right Way to AGI - After the LLMs” – July 2025, LinkedIn
“AI Therapist Goes Haywire, Urges User to Go on Killing Spree” – July 2025, Futurism
“Investors Are Suddenly Pulling Out of AI” – July 2025, Futurism
“Economist Warns the AI Bubble Is Worse Than Immediately Before the Dot-Com Implosion” – July 2025, Futurism
“OpenAI's New AI Agent Takes One Hour to Order Food and Recommends Visiting a Baseball Stadium in the Middle of the Ocean” – July 2025, Futurism
“Top AI Researchers Concerned They’re Losing the Ability to Understand What They’ve Created” – July 2025, Futurism
“A Leading Indicator Has Emerged Suggesting That the AI Industry Is Cooked” – July 2025, Futurism
“"Nonsensical Benchmark Hacking": Microsoft No Longer Believes OpenAI Is Capable of Achieving AGI” – July 2025, Futurism
“ChatGPT Has Already Polluted the Internet So Badly That It's Hobbling Future AI Development” – June 2025, Futurism
“How o3 and Grok 4 Accidentally Vindicated Neurosymbolic AI” – July 2025, Gary Marcus
“AI coding may not be helping as much as you think” – July 2025, Gary Marcus
“LLMs: Dishonest, unpredictable and potentially dangerous.” – June 2025, Gary Marcus
Why I'm Betting Against AI Agents in 2025 (Despite Building Them) - July, 2025
Doctors Horrified After Google's Healthcare AI Makes Up a Body Part That Does Not Exist in Humans - August, 2025
Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens
Bravo. One of a few true articles regarding AI. The way it's built right now it's just hype. It is useful in some cases, but far far away from cognition and AGI.
LLMs, big money, and big economy (including land grabs). Even in 2021 I remember conversations about the economics of big data and DL. We aren't out of that tide, yet.